7 листопада 2011 року, рік тому, я розповідав про CUDA на семінарі нашого інституту, присвяченому суперкомп'ютерним обчисленням. Однак, з того часу ніяк не вдавалося зібратися запостити розповідь тут. Цього року під час того ж семінару, знову повернувся до теми CUDA, акцентуючи увагу на готових рішеннях -- бібліотеках. Паралельно усвідомив, що відтягувати далі не варто.
Презентація доповіді 2011-го року можна скачати тут. Звичайно, з того часу вона встигла вже дещо застаріти. Нова, яка містить скорочений та оновлений варіант попередньої доповіді, плюс розповідь, із прикладами, про деякі бібліотеки CUDA -- тут. І одна і друга містить певну кількість помилок та неточностей. Побачите їх -- пишіть мені!
Ліцензія, як і всіх матеріалів у цьому блозі, якщо не сказано іншого -- Creative Commons Attribution ShareAlike.
Ліцензія, як і всіх матеріалів у цьому блозі, якщо не сказано іншого -- Creative Commons Attribution ShareAlike.
Перейду до того, що розповідалося. Текст нижче відповідає доповіді, писався так, щоб мені було зручно його промовляти, у наслідок чого не завжди підходить для представлення на письмі. Модифікував його зовсім трохи, тому сильно не гнівайтеся. :-)

Слайд 1
Сучасні процесори, які домінують на ринку персональних комп'ютерів та, завдяки Беовульф-кластерам, складають помітну частину ринку суперкомп'терів, належать до архітектури x86. Причини їх домінування, в основному, не технічні а економічні, не будемо зараз на цьому зупинятися.
Архітектура ця --- дуже давня. Її родоначальник, 8086, розроблявся в 1976-78 роках. Всі сучасні процесори, включаючи i7, бінарно сумісні з ним. При тому, він мав бути сумісний на рівні асемблера з 8080, 1974 року випуску, який у свою чергу був сумісним із 8008, 1972. Це була зовсім інша епоха, що дуже вплинуло на архітектуру. Наприклад, пам'ять тоді була швидшою за регістри процесора, тому регістрі загального використання мало. Безліч архітектурних розширень додали як свої помилки так і свої обхідні трюки для збереження сумісності. Кумедний приклад --- помилка в 286 стала дуже популярною і набула статусу стандарту в 386. Може ще хто пам'ятає himem.sys? Його роль --- "обслуговування" цієї помилки.
Архітектура ця --- дуже давня. Її родоначальник, 8086, розроблявся в 1976-78 роках. Всі сучасні процесори, включаючи i7, бінарно сумісні з ним. При тому, він мав бути сумісний на рівні асемблера з 8080, 1974 року випуску, який у свою чергу був сумісним із 8008, 1972. Це була зовсім інша епоха, що дуже вплинуло на архітектуру. Наприклад, пам'ять тоді була швидшою за регістри процесора, тому регістрі загального використання мало. Безліч архітектурних розширень додали як свої помилки так і свої обхідні трюки для збереження сумісності. Кумедний приклад --- помилка в 286 стала дуже популярною і набула статусу стандарту в 386. Може ще хто пам'ятає himem.sys? Його роль --- "обслуговування" цієї помилки.

Безвідносно до цього, процесори загального використання мають бути універсальними. Вони повинні добре виконувати один потік інструкцій, який, однак, може працювати з будь-якими даними, довільними розкиданими розгалуженнями та довільним доступом до пам'яті.
Разом із згаданою спадщиною, більша частина транзисторів процесора служить для вгадування --- як той код найшвидше виконати. При тому, борючись із тим, що система команд оптимізована під умови, які давно не існують.
Зростання тактової частоти не вихід, та й, крім того, воно зараз потроху впирається в чисто фізичні обмеження.
Розширення системи команд теж виявилося не дуже продуктивним --- компілятори (поки?) не вміють їх ефективно використовувати.
І це все --- не говорячи про енергоефективність...
Слайд 2
Один з перспективних способів обійти ці обмеження --- SIMD. Одна команда --- багато даних.
Включає такі розширення і архітектура x86. Не хотілося б вдаватися в деталі, тому дуже коротко. Процесор вміє працювати з кількома числами зразу. Зокрема, якщо він підтримує хоча б SSE2, то може виконувати операції з 4-ма 32-бітними числами з рухомою крапкою (float в термінології С) або з 2-ма 64-бітними, double. Найновіші процесори, що підтримують AVX, можуть працювати з вдвічі більшими кількостями величин.

Теоретичний приріст продуктивності -- 4 рази для float і 2 для double.
На практиці, Linpack, що використовується для тестування кластерів, та mkl від Intel, які оптимізовані "зі всіх сил", дають 75% від теоретичного приросту.
Однак, самостійне написання ефективного коду, що використовує SSE, складне! Вимагає великого професіоналізму, знання нюансів, та великих затрат часу. Автоматичні векторизатори компіляторів знаходяться у зародковому стані.
Слайд 3
Наприклад, якось так в коді на C++, виглядає додавання двох матриць розміром 2 на 2.

Слайд 4
Якщо сильно довіряєте своєму компілятору, можна робити трішки простіше. Однак при тому слід перевіряти згенерований код. Сюрпризи трапляються часто!

Слайд 5
Не маючи змоги збільшувати тактову частоту, виробники процесорів пішли природним шляхом збільшення кількості ядер.
Однак, в результаті, користувач, на додачу до необхідності освоювати нові технології паралельного програмування, отримуємо все вищеописане в кількох копіях.
Однак, в результаті, користувач, на додачу до необхідності освоювати нові технології паралельного програмування, отримуємо все вищеописане в кількох копіях.

Слайд 6
Обчислення, пов'язані з високоефективним виводом графіки, мають великий попит. Причина --- комп'ютерні ігри! Щоб розвантажити процесор, їх давно почали перекладати на допоміжні пристрої --- графічні прискорювачі, відеокарти. Обробка вершин та фрагментів (пікселів) відносно проста, обробляються вони незалежно один від одного. Однак, при тому їх потрібно
обробляти у дуже великих кількостях, і все --- в реальному часі. Тому місце на чіпі використовувалося для створення багатьох відносно простих процесорів. В наслідок цього відеокарти володіють величезним "вродженим" паралелізмом.
обробляти у дуже великих кількостях, і все --- в реальному часі. Тому місце на чіпі використовувалося для створення багатьох відносно простих процесорів. В наслідок цього відеокарти володіють величезним "вродженим" паралелізмом.

Спочатку вони вміли виконувати лише зашиті у них прості алгоритми, поступово гнучкість зростала, з'явилася можливість задавати алгоритми обробки. Це привело до спроб використовувати відеокарти для обчислень. Виникла окрема область --- "Обчислення загального призначення на графічних процесорах". Однак, щоб використовувати відеокатру для обчислень, доводилося "робити вигляд", що опрацьовуються зображення. При цьому необіхдно користуватися графічним API, зберігати дані як текстури, обробляти їх, пишучи шейдери, тощо. В наслідок цього, технологія GPGPU розвивалася повільно, і не набула особливого поширення.
На початку 2007 nVidia запропонувала технологію, що дозволяє використовувати її відеокарти для обчислень --- Compute Unified Device Architecture, CUDA. Програмування здійснюється дещо урізаним варіантом C чи С++, доповненим кількома ключовими словами. Про неї трішки пізніше.
Конкуренти ATI/AMD, запропонували свій аналог, Close to Metal/Stream Computing SDK, однак популярності вона не завоювала і до тепер фактично відмерла (а компанія зосередила свої зусилля на OpenCL).
В кінці 2008 було випущено OpenCL, технологію розробки гетерогенних обчислювальних систем. Вона працює на пристроях виробництва nVidia, ATI/AMD, звичайних x86-сумісних процесорах, тощо? та, в теорії, на їх різноманітних комбінаціях. Базується на С99. Так як, на момент виходу, найбільш зріле рішення було у nVidia, OpenCL має з CUDA багато спільного.
Як завжди, Microsoft запропонувала свою технологію --- DirectCompute, (і, в 2012 -- C++AMP), але сказати що із цього буде поки важко. Сподіватимемося, цю індустрію їм зіпсувати не вдасться.
Слайд 7
Далі розмова йтиме про технологію CUDA. Для початку, графік від nVidia, з порівнянням росту теоретичної продуктивності процесорів та відеокарт.

Як бачимо, розрив вражаючий. Хоча, компанія трохи лукавить, зокрема, "добути" помітну частку теоретичної продуктивності з процесора багато простіше, ніж з відеокарти, але все рівно технологія вартує уваги.
Слайд 8
Що ж таке оця CUDA?
Як колись говорили -- програмно-апаратний комплекс. Його апаратна частина включає власне обчислювальний пристрій та його виділену пам'ять. Програмна частина -- спеціалізовані компілятор та асемблер, для програмування пристрою та різноманітні бібліотеки, оптимізовані для відповідного пристрою.
Традиційно архітектуру CUDA описують зверху вниз, починаючи від програмних абстракцій та інтерфейсів. Однак це ускладнює розуміння механізму роботи пристрою, яке є важливим для написання ефективних програм. (Ну, або фізику простіше починати "знизу" :)
Як колись говорили -- програмно-апаратний комплекс. Його апаратна частина включає власне обчислювальний пристрій та його виділену пам'ять. Програмна частина -- спеціалізовані компілятор та асемблер, для програмування пристрою та різноманітні бібліотеки, оптимізовані для відповідного пристрою.
Традиційно архітектуру CUDA описують зверху вниз, починаючи від програмних абстракцій та інтерфейсів. Однак це ускладнює розуміння механізму роботи пристрою, яке є важливим для написання ефективних програм. (Ну, або фізику простіше починати "знизу" :)

Забігаючи наперед скажу, що на відміну від процесора, який намагається виконувати ефективно майже будь-який код, ті чи інші графічні процесори очікують допомоги від програміста. Різниця в продуктивності може складати два порядки.
Увага, CUDA-пристрій є, фактично, сопроцесором. Він включає декілька мультипроцесорів та свою виділену пам'ять. Центральний процесор ставить перед ним задачі і забирає результати. Розглянемо мультипроцесор детальніше.
Слайд 9
Це виділений обчислювальний пристрій, із цілим рядом своїх ресурсів -- обчислювальних блоків різних видів, та кількох видів пам'яті. Їх кількість та набір залежить від моделі пристрою. Щоб розрізняти різні їх типи, вводять спеціальне поняття Compute Capability, своєрідну версію. Не слід плутати її із версією самої CUDA. Забігаючи наперед, архітектура така, що на кожному мультипроцесорі логічно одночасно виконується (прив'язані до нього) багато потоків. Однак, одночасно він може виконувати лише стільки операцій, скільки є відповідних пристроїв, скажімо 8 цілочисельних додавань, але лише дві 64-бітні арифметичні операції.

Слайд 10
Обчислювальні блоки мультипроцесора (таблиця з доповіді 2011-го, нижче буде новіша, з доповіді 2012):

Слайд 11
Ситуація з пам'яттю, на відміну від процесорів, де є єдина спільна пам'ять та прозорий кеш, значно складніша. Її аж шість різних видів. Програміст мусить спланувати та запрограмувати її використання для досягнення максимальної ефективності. Частина розташована на мультипроцесорі. Її об'єм відносно малий, але вона швидка. Скажімо, регістрів може бути приблизно 8 тисяч, 16 чи 32 тисячі, однак так як вони розподіляються між всіма потоками, прив'язаними до даного мультипроцесора, це не дуже багато.

Інші види знаходяться у виділеній пам'яті графічного пристрою, при чому константна та текстурна -- кешуються, доступ до них відносно швидкий, а так-звані глобальна та локальна --- можуть кешуватися лише в пристроях версії 2, і то з рядом обмежень (та ж фізична область пам'яті на мультипроцесорі використовується для автоматичного кешу та колективної пам'яті), даючи час доступу в сотні тактів.
Щоб ще ускладнити ситуацію, для покращення швидкодії, звертання до різних адресів пам'яті різними потоками мають відбуватися згідно певних правил. Про них трішки пізніше, але їх недотримання призводить до падіння продуктивностів разів у 16.
Зауважу, що тут дуже багато деталей опущено, просто за відсутністю достатнього часу.
Слайд 12
Поглянемо тепер на пристрій з точки зору програмної архітектури. Конкретну програму, що виконується на пристрої, називають ядром, kernel. Вона виконується, в певному сенсі, одночасно, для всіх елементів даних, що обробляються. Одну її копію, що працює із певним набором даних, називають потоком ("ниткою", "thread").
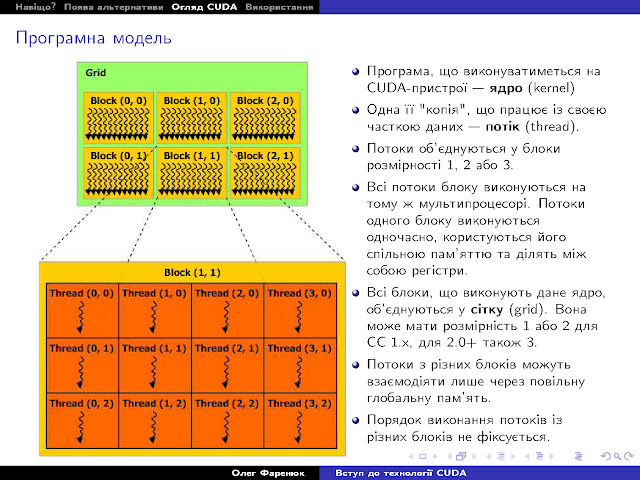
Потоки логічно об'єднуються у одно, дво- чи трьохмірні блоки. Кожен блок, на загал (як завжди, є нюанси, але не буду заглиблюватися), виконується на своєму мультипроцесорі, користуючись його ресурсами. Потоки в межах одного блоку користуються тією ж спільною пам'яттю та можуть обмінюватися даними. Взаємний порядок виконання потоків не фіксується, тому слід користуватися синхронізацією. Вважається, що в межах блоку всі потоки виконуються одночасно. Тому слід бути обережним із спільними даними.
Всі блоки, що виконують те ж ядро, об'єднуються в одно- чи двохмірну сітку (трьохмірну на новіших), "грід". Різні блоки в межах гріду можуть взаємодіяти лише через глобальну пам'ять, звертання до якої дуже повільні. Тому бажано таку взаємодію мінімізувати.
Потоки логічно об'єднуються у одно, дво- чи трьохмірні блоки. Кожен блок, на загал (як завжди, є нюанси, але не буду заглиблюватися), виконується на своєму мультипроцесорі, користуючись його ресурсами. Потоки в межах одного блоку користуються тією ж спільною пам'яттю та можуть обмінюватися даними. Взаємний порядок виконання потоків не фіксується, тому слід користуватися синхронізацією. Вважається, що в межах блоку всі потоки виконуються одночасно. Тому слід бути обережним із спільними даними.
Всі блоки, що виконують те ж ядро, об'єднуються в одно- чи двохмірну сітку (трьохмірну на новіших), "грід". Різні блоки в межах гріду можуть взаємодіяти лише через глобальну пам'ять, звертання до якої дуже повільні. Тому бажано таку взаємодію мінімізувати.
Слайд 13

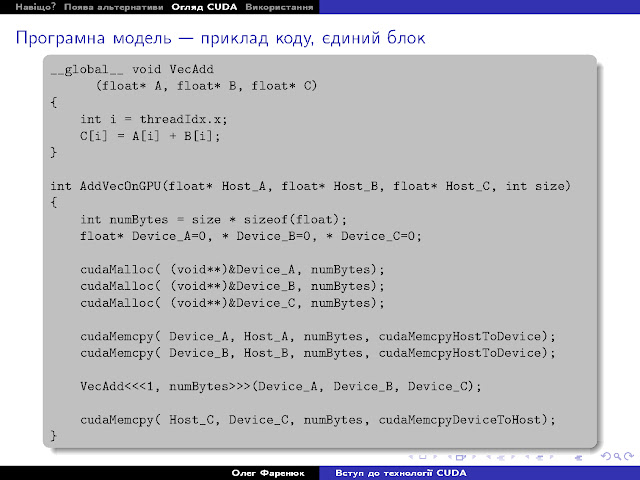
Подивимося як все це працює. Нехай ми хочемо попросити пристрій додати нам два вектори. Зауважу, що таке використання пристрою є абсолютно неефективним, наводиться лише для ілюстрації. Отож, код, що виконуватиметься на графічному процесорі, вказується специфікатором global. Йому передається ряд вбудованих змінних, що дозволяють конкретному потоку довідатися про свою ділянку роботи. В наведеному прикладі використовується одна із них --- threadIdx, трьохмірна координата потоку в блоці. В нашому прикладі нульовий потік додає нульові елементи векторів, перший --- перші, і так далі.
Директива виклику ядра виглядає наступним чином: <<< ... >>>, їй передається кількість блоків у сітці (1, для простоти) та кількість потоків у блоці (N). В даному прикладі ми звертаємося до драйвера та рантайму CUDA з проханням створити сітку з одного одномірного блоку розміром N, та виконати ядро VecAdd.
Весь цей код виконуватиметься на одному мультипроцесорі, адже блок один.
Кілька слів про те, як саме відбувається виконання.
Слайд 14
Всі потоки одного блока розбиваються на послідовності, так звані ворпи (warp) --- не знаю, як перекласти. На всіх сучасних пристроях warp це 32 потоки, але це число може змінюватися з часом. Потоки одного warp-а мають послідовні індекси (з 0 по 31, з 32 по 63 і т.д.), та виконуються логічно одночасно. При тому, що найбільш важливо, всі його потоки повинні виконувати одну і ту ж інструкцію. Шлях виконання програми, одначе, може відрізнятися для різних потоків. Це вирішується просто. Якщо в програмі є розгалуження, if, і частина потоків вибирає одну гілку, частина іншу, то спершу виконуватимуться ті потоки, що вибрали перший варіант, а потім ті, що другий. Це сильно полегшує програмування, і є важливою відмінністю від SIMD моделі, про яку згадувалося раніше. Однак, в найгіршому варіанті швидкість виконання warp-а може бути в 32 рази менша максимальної. Це слід враховувати, програмуючи! Часто вигідніше робити зайву роботу, дозволяючи частині потоків крутитися "порожняком", лише щоб весь warp йшов однією гілкою. Компілятор намагається допомагати, вставляючи точки синхронізації-сходження різних гілок та умовні інструкції, які виконуються лише коли певний прапорець істинний.

Згадаємо, що кількість виконавчих пристроїв мультипроцесора різна, часто менша 32. Якщо, наприклад, warp виконує цілочисельне додавання, а відповідних пристроїв тільки вісім, то виконання однієї інструкції для всіх 32 його потоків займе 4 такти. Однак логічно всі вони відбуваються одночасно, тобто, наприклад, неатомарні звертання до пам'яті відбуватимуться у довільному порядку. Зокрема, якщо мова про запис, то не можна передбачити, котрий із потоків здійснить запис останнім.
Якщо звертання до пам'яті різних потоків відбуваються згідно певних правил, вони об'єднуються (coalescing). В деталі вдаватися не буду, скажу тільки, що на старих пристроях вони були дуже жорсткими, а порушення сповільнювало роботу в 16 раз. На сучасних -- простіше, але теж вимагає акуратності.
Слайд 15
Повернемося, однак, до прикладу
програми. З ним не все так просто. Вказівники A, B, C не можуть
звичайними вказівниками, так як хост та пристрою мають свою пам'ять.
Спочатку потрібно виділити пам'ять на пристрої, потім скопіювати туди
дані для роботи, і вже ці вказівники, які знаходяться фізично в іншому
вимірі, передати ядру.
Слайд 16
На остаток ще трішки доповнимо цей приклад. Для підвищення ефективності слід завдання розподілити між всіма мультипроцесорами, запустивши багато блоків.

Слайд 17
Апаратні ресурси, доступні в різних версіях Compute Capability, наведені тут (таблиця з доповіді 2011-го, нижче буде новіша, з доповіді 2012):

Слайд 18

Слайд 19
Коротко про процедуру інсталяції (слайд старий, нещодавно, в жовтні 2012, вийшла версія 5.0):

Слайд 20
Список бібліотек CUDA:

Включено cuFFT, cuBLAS, cuSPARSE, CUSP, cuRAND, Thrust, NPP, CUDA Math library, MAGMA, ArrayFire (була libJacket), CULA tools, IMSL.
Слайд 21
Приклад використання Thrust:

Слайд 22
Приклад використання комерційної бібліотеки CULA:

Слайд 23
Програмні пакети, що декларують підтримку CUDA:

Слайд 24
Наша карточка:

Слайд 25
Результати декількох тестів:
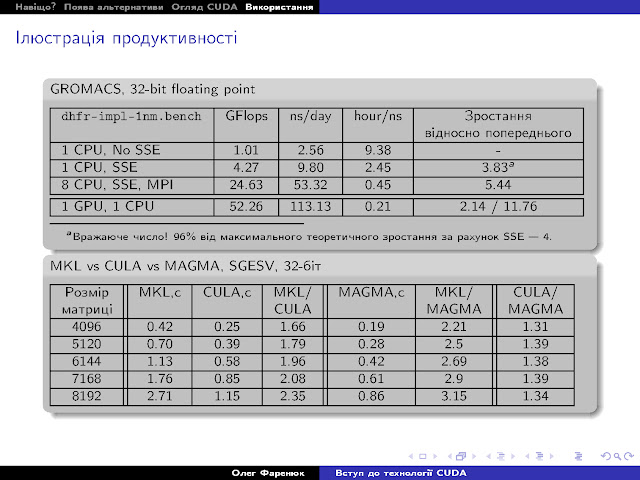
Як видно, для GROMACS виграш суттєвий, а Open Source MAGMA (реалізація LAPACK для CUDA, від тієї ж команди, що власне LAPACK а потім і ScaLAPACK розробляла) помітно обганяє комерційну CULA, а вони обидві сильно обганяють одну з найкращих матричних бібліотек для Intel-сумісних CPU, яка активно використовує всілякі SSE, MKL.
Слайд 26
Додаткові джерела інформації:

В продовження теми, частина слайдів доповіді 2012 року
Обчислювальні блоки мультипроцесора, оновлена таблиця:


Слайд 2-13
Якщо є можливість, не слід займатися велосипедобудуванням. ;-)

Слайд 2-14
Бібліотеки, що входять до складу SDK:

Слайд 2-15
Open Source та комерційні бібліотеки:

Слайди 2-16 -- 2-21
Огляд бібліотеки алгоритмів Thrust, близькою за ідеологією до стандартної бібліотеки шаблонів STL (C++).
Основні елементи: host_vector, device_vector, device_ptr, алгоритми reduce, transform, sort, count_if і т.д., розширені ітератори -- constant_iterator (вказує на константу, фактично зображає безмежну структуру із тим самим значенням всіх елементів), counting_iterator (повертає збільшені елементи за кожного його збільшення), transform_iterator (виконує більш складні перетворення), zip_iterator (дозволяє прозоро перейти від зручного, але повільного масиву структур, до швидкої, але не дуже зручної структури масивів).




Злиття операцій:

Слайд 2-22
Бібліотека генерації випадкових чисел:

Слайд 2-23

Слайд 2-24 -- 2-25
MAGMA --- LAPACK для CUDA:


Слайди 2-26 -- 2-27
Ще одна матрична бібліотека, на цей раз C++, бібліотека роботи із розрідженими матрицями:

Бібліотека не надає повного комплекту засобів для роботи з матрицями (як вже згаданий LAPACK чи eigen), однак, коли стоїть задача розв'язати розріджену систему лінійних рівнянь, розміром, так, мільярд на мільярд, не така вже це й велика плата за ефективність.

Слайд 2-28
Для повноти викладу, приклад використання CULA:

Слайд 2-29 -- 2-30
Швидке перетворення Фур'є, FFT, бібліотека cuFFT


Слайд 32
Мови програмування, з яких можна скористатися CUDA:

Слайд 34
І, на останок, невелике доповнення щодо літератури: Сайт NVidia містить списки бібліотек та програм, які використовують CUDA. Реєстрація на їх порталі для розробників (вимагає підтвердження від адміністраторів, але науковців які мінімально акуратно заповнили форму, підтверджують швидко) відкриває доступ до багатьох цікавих продуктів та матеріалів.
На цьому ---
ДЯКУЮ ЗА УВАГУ!
Якщо є запитання, виправлення, пропозиції -- пишіть.
Немає коментарів:
Дописати коментар